Everyone lives in a bubble, and all models are overfitted
I beseech you, in the bowels of Christ, think it possible you may be mistaken. - Oliver Cromwell
Real knowledge is to know the extent of one’s ignorance. - Confucius
So, a lot of people are saying the media/elite got the election wrong because they live in a ‘bubble’.
And some are saying the pollsters and forecasters were all wrong and ‘data science’ is bullshit.
Well, this guy models, sometimes, and if you say that, you’re all as full of shit as the pundits and forecasters, and in most cases far more so.
Sure…media, analysts, Silicon Valley live in a bubble…unlike rural farmers who take time out of each day to consult a broad cross-section of Americans. (via this guy)
Sure…Nate Silver is full of BS…but an unemployed coal-miner who thinks Obama’s birth certificate is fake and Trump is going to build a wall and bring back his job is keeping it real.
The only way anyone can make sense of reality is by filtering it. We all create our own bubbles.
The only reality anyone knows is socially constructed, and subject to our own heuristics and behavioral biases.
Any sufficiently powerful model will overfit to past (in-sample) data, compared to the future (out-of-sample). The only way to prevent that is to pad the error bars for what you don’t know you don’t know, and build in a bias toward uncertainty.
What forecasters do is fight the curse of dimensionality and try to find the bias/variance sweet spot.
Fighting dimensionality means trying to explain a lot of variables with a few, finding simple patterns in complex data. The problem is, reality is incredibly messy, and the messier it is, the easier it is to find spurious patterns.
You can have an ultra-simple model, like a simple linear regression, and it may not fit the data very well, because the underlying reality is not linear, or because multiple predictors impact the response.
These models are biased in the sense that they start from an opinion about the data, a linear response to a single predictor, that is not true in reality.
So then you add variables and relax the linearity assumption, and if you do a good job your model starts to fit the in-sample data well and predicts the future a little better.
But if you add enough complexity to your model, you start to fit the quirks in your data too well, and your out-of-sample prediction gets worse. Instead of being overly wedded to the bias of your a priori model, you are overly sensitive to random variance in the data you happen to have encountered.
The tradeoff looks like this, via Scott Fortmann-Roe:
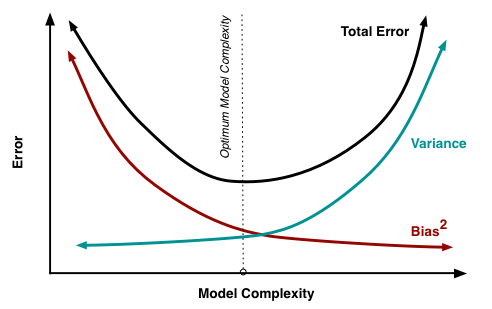
The data scientist is looking for that trough in the black line, the right balance between underfitting and overfitting, and trying to understand reality as well as possible to make the trough as deep as possible.
One thing data scientists do is divide data into training and test sets. You fit a model on the training set and then use the test set to measure the training error. Now maybe you go back and try a bunch of models and see which one performs best. Well, guess what, now you’ve selected a model using the test set, so you are in that sense fitting to the test set. By regression to the mean, you are more likely to select a model that got at least a little lucky, and your future performance will not match the test set.
So now you split into 3 sets, training to fit your model, cross-validation to select and fine-tune the model, and a test set, which you never look at until you are ready to predict your out-of-sample error. That should work in theory. But in practice, after that you will at some point go back and make adjustments based on out-of-sample performance. It’s very hard to stick 100% to that principle, although most scientists do so well enough that most results are correct. (Cough…Not! And yet that’s the nature of good science.)
Pollsters ask questions to determine whether respondents are likely voters. Then they predict whether they will actually vote based on past election data, and adjust sample weights accordingly. And there’s error from sampling variation, from your prediction of likely voters, from your sampling of past polls that you use to estimate the error of that prediction. It’s turtles all the way down. And if one particular type of voter is particularly excited to vote this election based on something that never happened in the past, you’re just not going to catch it. You just hope all the errors cancel out.
One of the funny concepts that I think is recent in machine learning is an emphasis on ‘worse is better.’
- Regularization can add a penalty to really significant parameters on the theory that the most significant parameters got a bit lucky.
- Dropout trains a neural network using only e.g. 50% of the neurons each iteration, so that the network develops independent paths to the correct result. Sounds nuts. Maybe it’s like shooting a basketball until you’re so tired you can’t see or feel your fingers, and it becomes automatic.
- Random forests use an algorithm that builds a large number of decision trees which each use a randomly selected subset of predictors, and have them vote on the outcome. Kind of like a bunch of people who each see a different side of a jar of jelly beans vote on how many black beans there are. Again, sounds nuts until you see it work.
(Machine learning feels like street-fighting statistics. If it works in a well-designed out-of-sample test, use it. Throw out any opinionated model about what data looks like and where it comes from, and don’t worry about proofs or elegance.)
Nate Silver gave Trump 35% and thoroughly explained the limitations of that analysis. He said Trump was within a normal polling error. Does that make him an idiot? If his probability prediction is always perfect, he’s going to be an idiot 1 election out of 3 and a genius 2 out of 3. Others maybe not so much.
The Nate Silvers, and media, and Silicon Valley, are the guys confronting reality, creating it, with the best tools they have. Maybe they’re in a bubble, but they try to make it the most self-aware, attentive, deliberate bubble they can.
Those in the so-called ‘media/elite bubble’ get a lot of flak for both being too mainstream, and too sensitive to minority views. (i.e. both too much bias, and too much variance.)
Everyone’s models of the world are overfitted to their own experience…unless they make an intense, deliberate effort to appreciate others’ experiences…to back off a little from assuming our experience is the complete reality. If we’d been born where they were born, taught what they were taught, and lived what they live, we would live in their bubble, and believe what they believe.
I believe Trump and his followers should, for example, accept the reality of Obama’s birth certificate, and firmly reject the endorsement of the KKK. If they don’t, it seems like they need to get out of their own bubble and tolerate others. My acknowledging and appreciating your reality cannot always extend to conforming mine to yours.
The beautiful thing about science, and markets, and democracies, is that for all their faults, they harness the potential and decision-making of all participants, and when they screw up, they eventually self-correct.
It is a mistake to try to look too far ahead. The chain of destiny can only be grasped one link at a time. _ Sir Winston Churchill
(inspiration credit to @firoozye)